
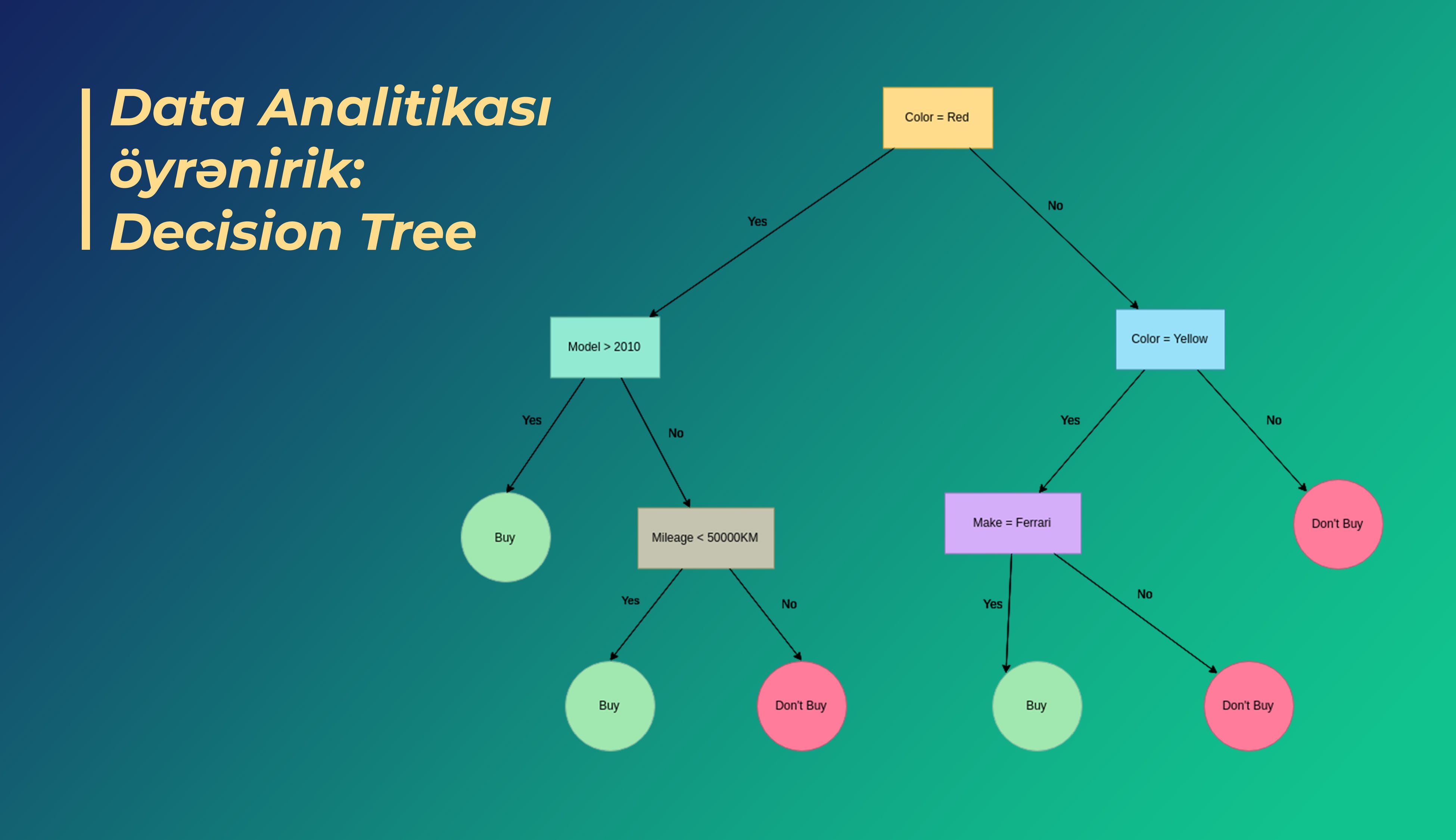
Decision Tree - Qərar ağacı-maşın öyrənmə alqoritmi
Bir çox qurumlar və şirkətlər öz verilənlər bazalarını dəyərli məlumatlar ilə(əsasən müştərilərə dair) zənginləşdirərək inkişaf prosesində yüksək nəticələrə nail olurlar, çünki bu metod onlara müştərilərin ehtiyaclarını müəyyən etməyə yardım edir. Lakin, bu verilənlərdən informasiyanın effektiv çıxarışı və gizli qanunauyğunluqların tapılması maşın öyrənmə alqoritmlərin istifadəsini zəruri edir. Qərar ağacı alqoritmi(Decision tree) klassifikasiya və ehtimal kimi məqsədlər üçün ən çox istifadə edilir.
Decision tree tətbiq sahələri
Tətbiq sahələrinə gəldikdə isə, müştəri münasibətlərinin idarəedilməsi, bank hesablarında fırıldaqçılıqların aşkarlanması, enerji istehlakı, tibb kimi sahələrdə istifadə olunur. Məsələn, Enerji istehlakı şəxslərin elektrikdən nə qədər istifadə etməsi barədədir. Bu istiqamətdə olan araşdırmalar şirkətlərə lazım olan enerji miqdarını gərəkli vaxtda müəyyən etməyə kömək edir. Qərar ağacı metodunun hiyerarxik strukturu informasiyanın vizual olaraq aydın və dəqiq göstərilməsini təmin edir. Havanı dumanlı, yağışlı və ya qasırğalı olacağını proqnozlaşdırmaq üçün orta temperatur, rütubət və təzyiq kimi xüsusiyyətləri nəzərə alaraq, bu alqoritmi qurmaq mümkündür.
Təsəvvür edin ki, sizin bir tibbi araşdırmanız üçün xəstələrə aid verilənləriniz(data) var hansılar ki eyni xəstəlikdən əziyyət çəkirlər. Müalicə periodu ərzində, xəstələrin Yaşı, Cinsi, Qan təyziqi və Xolesterolu verilənlər toplusunun xususiyyətləri(features) kimi qeyd olunmuşdur və həkim tərəfindən dərman 3 növü bu dəyişənlərə əsasən xəstələrə təyin edilmişdi: , Drug A, Drug B, Drug C.
Sizin əsas işiniz isə bu xəstəlikdən əziyyət çəkən gələcək xəstələrə ən uyğun dərman növünü onların Yaşı, Cinsi, Qan təyziqi və Xolesterolu əsasında təxmin etməkdir.
Bu klassifikasiya növündən istifadə edərək, Siz verilənlərin “training” hissəsini qərar ağacı qurmaq üçün və yeni xəstənin hansı qrupa aid olduğunu xəbər vermiş olacaqsınız.
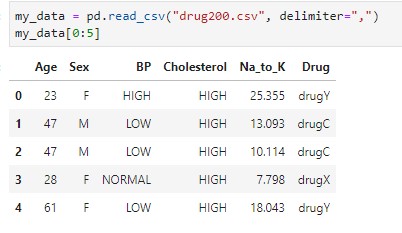
Əvvəl verilənləri Panda kitabxanasının funksiyası ilə çağıraq və nümayiş etdirək:

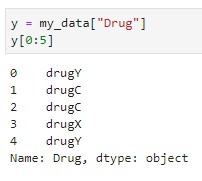
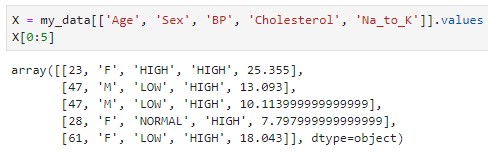
2 əlavə dəyişən yaradaq:
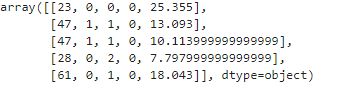
X- my_data adlı verilənlər toplusunun matriksi(dərman növü ehtimal edilməsi lazım olan xususiyyət olduğundan atılmışdır)
y- cavab vektoru(response vector)- əsas hədəf


Bəzi xususiyyətlərin(features) rəqəmlə ifadə olmadığını müşahidə edirik(məsələn cins və təzyiq) və Python proqramlaşdırma dilinin Sklearn kitabxanası bu səbəbdən düzgün çalışa bilmədiyindən, biz kateqorik dəyişənləri 0 və 1lər ilə əvəz edirik:


İndi isə verilənlər toplusunu 2 ayrı hissəyə bölək: Train and Test. Training datası təyin edilmiş dərman növlərini özündə cəmləşdirir və ondan istifadə edərək yeni xəstəyə hansı dərmanın uyğun olması müəyyən edilir. Test verilən toplusu isə bizə qurduğumuz modelin ehtimalını yoxlamağa imkan verir.
|
Training =70 |
Test =30 |




Burada göstərilən test_size=0.3, Verilənlərin 70%-ni Training toplusuna və 30% Test toplusuna daxil etdiyimizi bildirir.
İndi isə dərman növünü təyin etməyə kömək edən modelimizi- qərar ağacını qurmağa başlayaq:


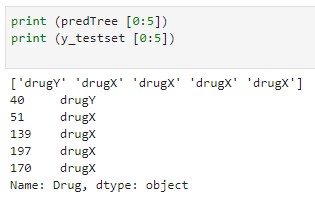
Daha sonra Test verilənlər toplusu üzərində bir neçə xəstəyə uyğun dərman növlərini ehtimal edək



Qərar ağacını Vizuallaşdırmaq üçün isə aşağıdakı yazmağa gərək var:



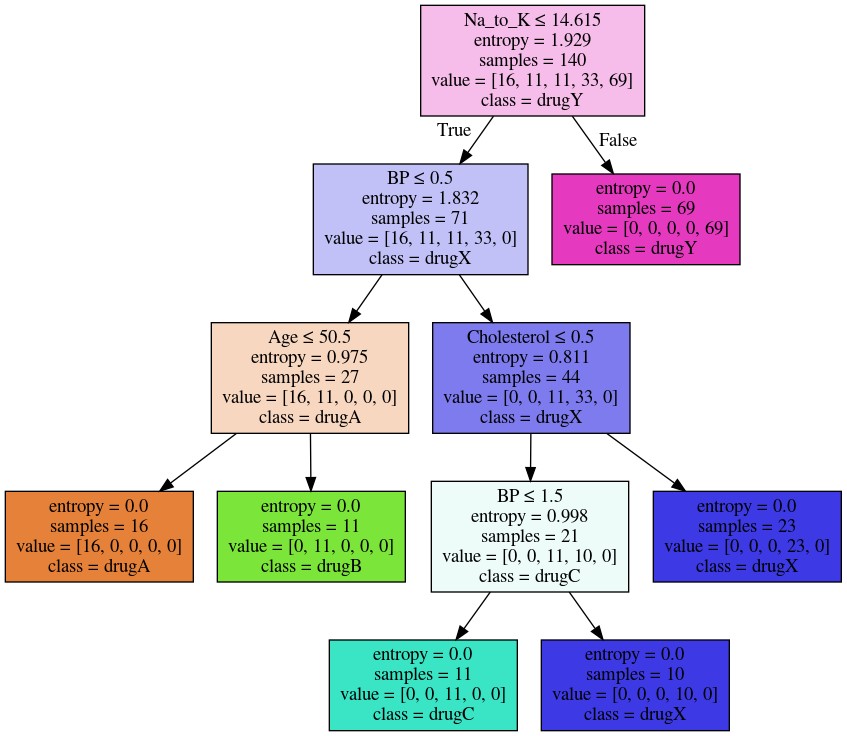


Bu diaqramı daha aydın başa düşmək üçün, alqoritmdə qərarların necə verildiyinə yaxından baxaq.

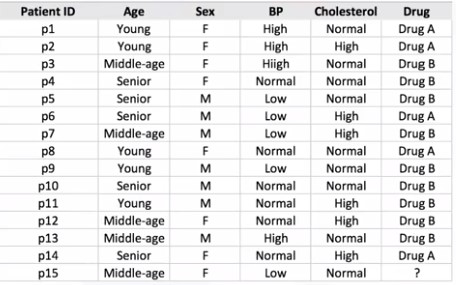
Burada 14 xəstəyə aid məlumatlar verilmişdir və bu alqoritm sayəsində biz ən yaxşı ehtimal(the most predictive) edən xususiyyəti(feature) seçməliyik.
Məsələn, xolestorolu ilkin xususiyyət(və ya atrtibut) kimi seçdikdə, görərik ki bizim verilənlərimiz bunun nəticəsində əlavə iki hissəyə ayrılırlar hansılar ki hər iki dərman növü daxildir. Bu kimi pis xususiyyətlərin seçilməsi bizə fərziyyələrimizdə əminlik vermir, çünki bu ayrıma çox qarışıq və dəqiqlikdən uzaqdır :

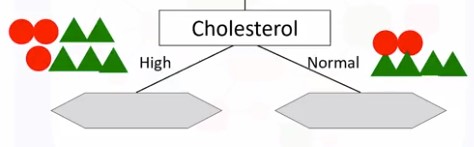


Bu dəfə artıq xəstənin cinsiyyətinin ilkin xususiyyət kimi seçək və verilənlərin yenə iki hissəyə ayrıldığını müşahidə etmiş olarıq.

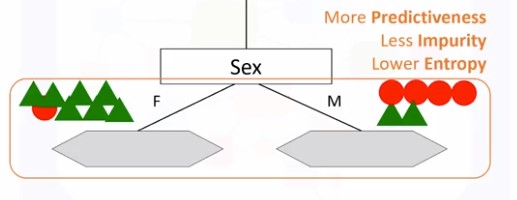


Burada aydın olur ki, əgər xəstəmiz qadındırsa, o zaman DrugB ən uyğun dərman növü olduğunu fərz etmiş olarıq. Lakin, əgər xəstəmiz kişidirsə, biz hər hansı dərman növünü əminliklə təyin edə bilmərik. Bunun üçün biz növbəti dəfə də xüsusiyyət seçərək dərman növünü təyin etməliyik:


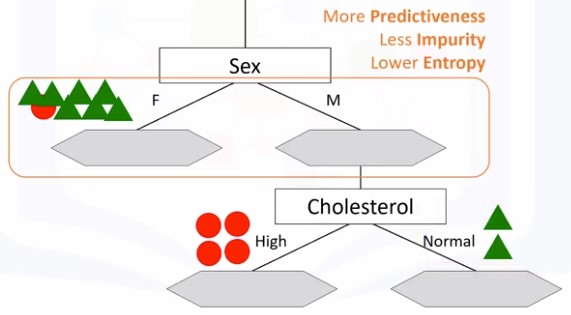

Bu dəfə ki bölünmə nəticəsində daha aydın və dəqiq nəticə alırıq. Başqa sözlə, verilənlər toplusunu hər dəfəsində(düzgün xüsusiyyəti seçdikdə) böldükdə, biz mürəkkəb olmayan toplular əldə etmış oluruq- yalnız DrugA yüksək xolesterol olan xəstələrə və yalnız DrugB normal xolesterolu olanlara. Əlavə olaraq, Entropy adlı anlayışı vurğulamağa ehtiyac var və bu göstərici hər düyündə(bölünmüş topluda) verilənlərin ixtiyari və qeyri-müəyyən paylanmasını ölçür. Biz də öz düyünlərimizdə bu göstəricinin az olmağını tərcih edirik, çünki Enthropy bizim ehtimallarımıza əhəmiyyət və əminlik verir.

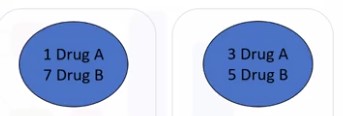


Entropy azdır Entropy çoxdur
Daha çox oxu: