
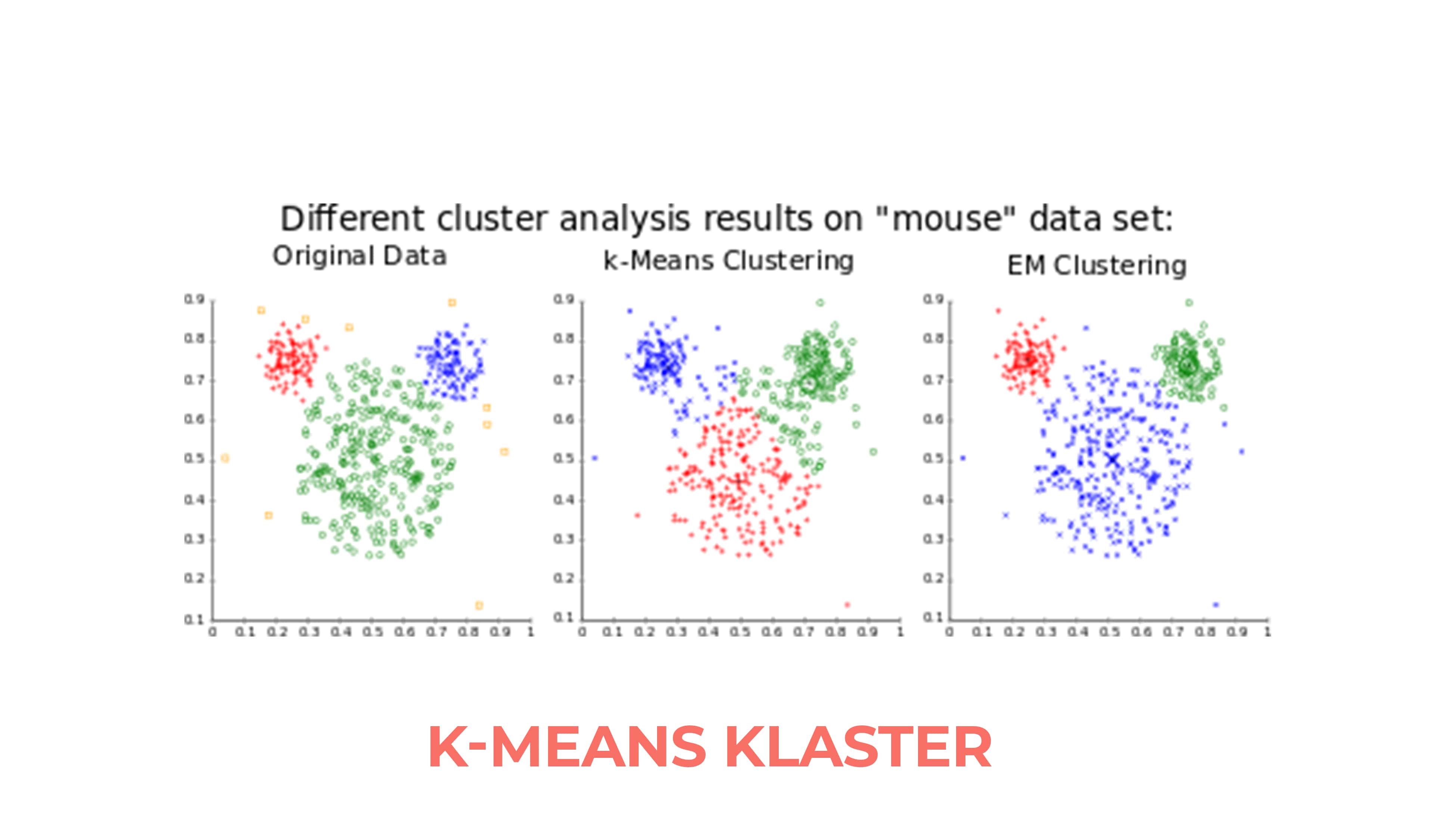
K-means Klaster(K-means Clustering) alqoritmi
Klaster analizi müştərilərin oxşar davranışlarını müəyyən etmək üçün, şəkillərin keyfiyyətini itirmədən sıxılması(compression) və ya seqmentasiyası üçün istifadə edilir.
K-means Klaster Alqoritminin tətbiq sahələri:
-
Müştəri məlumatlarının qruplaşdırması(ödəniş etdikləri məhsullar, onların sayı, qiyməti və digər xərcləmə davranışları)
-
Qanunsuzluqların aşkarlanması
-
Xəbər veb səhifələrinin(məsələn,Facebook NewsFeed) nizamlanması
-
Ətraf mühitin təhlükədə olduğu yerlərin aşkarlanması
-
Reklamların sizin əvvəlki axtarış sorğularınız əsasında veb səhifələrdə yerləşdirilməsi
K-Means Klaster Alqoritmin tətbiqinə ehtiyac olan nümunəvi hal:
Bir Pizza hazırlayan şirkət məhsulun çatdırılması mərkəzlərini açmaq niyyətindədir. Sizcə onların üzləşdiyi çətinliklər hansılar ola bilər?
-
Onlar tez-tez sifarişlərin verildiyi əraziləri nəzərdən keçirməlidirlər.
-
Onlar açılması gərəkən pizza satılan mağazalarının sayını bilməlidirlər ki, məhsulun çatdırılmasını təmin etsinlər.
-
Onlar pizza satılan mağazaların yerləşəcəyi əraziləri ən uyğun şəkildə müəyyən etməlidirlər ki, çatdırılma mərkəzləri arasında olan məsafə minimum olsun.
Klaster alqoritmi verilənlər toplusunun strukturu(ardıcıllıq) barədə informasiya verir və verilənlər(data) analizini yerinə yetirmək üçün ən çox istifadə edilən metodlardandır. Əsas məqsəd verilənlər toplusunda alt qruplarının(oxşar verilənlər nöqtəsi toplusu) müəyyən edilməsidir. Başqa sözlə, verilənlər toplusunda(dataset) oxşarlıq ölçüsünə əsaslanaraq verilənlərin alt qruplara ayrılması nəzərdə tutulur. Oxşarlıq ölçüsü verilənlər nöqtələri(data points) arasında məsafə ilə hesablanır.
Bildiyimiz kimi, Machine Learning üsullarının 2 növü var: Supervised və Unsupervised. Klaster alqoritmi Unsupervised öyrənmə üsuluna aiddir, çünki bu alqoritmin nəticəsini (output) digər doğru hesablanmış nəticələr (labels) ilə müqayisəsi mümkün deyil. Biz sadəcə verilənlər toplumunun strukturunu (the structure of the data) verilənlər nöqtələrinin (data points) qruplaşdırılması ilə araşdırırıq.
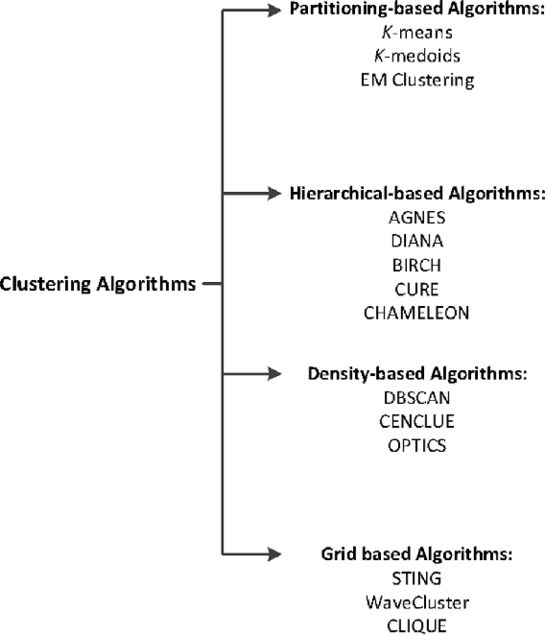
Klaster alqoritmlərinin növləri aşağıdakı kimi verilmişdir:
Biz yalnız ən sadə Klaster alqoritmi olan- K-means Klaster alqoritmin həm riyazi hesablanmasını həm də Python proqramlaşdırma dilində real verilənlər toplusu (dataset) üzərində analizini vermişik.
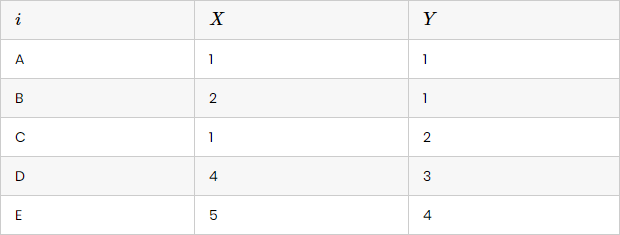
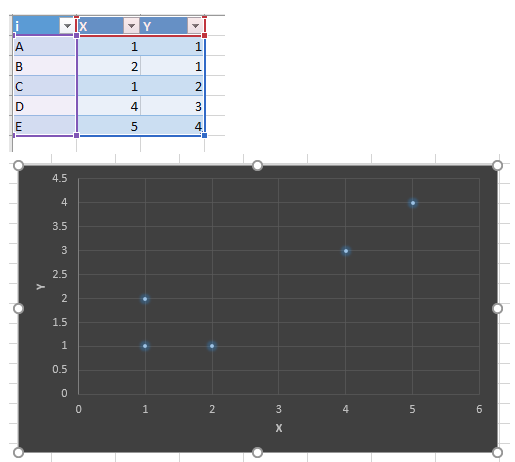
Aşağıda verilmiş verilənlər toplumunun klasterlərini tapmağa çalışaq:
Addım1. Klasterlərin sayını müəyyən etmək.
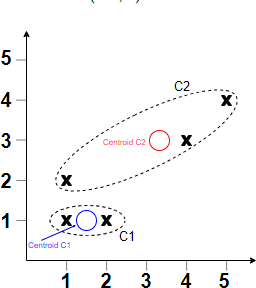
Bu alqoritm K sayda klasterləri əvvəlcədən müəyyən etməyi tələb edir. Bu halda k=2 götürürük, çünki qrafikdən görünür ki, 2 növ qruplaşma əmələ gəlib: aşağı-sol və yuxarı-sağ künclərdə.
Addım2. Verilənlər nöqtələrinin(Data points) təyin edilməsi.
Bu mərhələdə hər nöqtə ən yaxın olan klaster mərkəzinə təyin edilir. Klaster mərkəzlərinə həm də cazibə mərkəzləri kimi də təsəvvür etmək olar. Əvvəlcə, mərkəz nöqtələrini təsadüf nöqtələrdən seçirik: mərkəz nöqtə 1 - A(1,1) və mərkəz nöqtə 2 - C(1,2)
Ən yaxın klaster mərkəzini hesablamaq üçün adi Evklid nöqtələr arasında məsafəni hesablamaq üçün

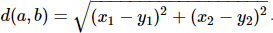
düstürundan istifadə edirik:
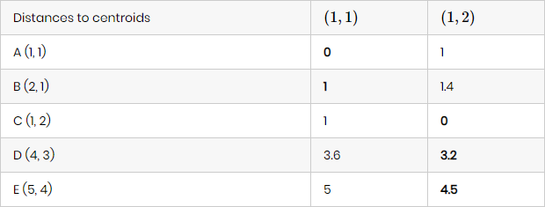
Məsələn, E(5,4) nöqtəsi və mərkəzi nöqtə olan C(1,2) nöqtəsi arasındakı məsafə belə hesablanır:

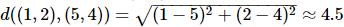
Bununla belə, biz nöqtələri klasterlərə onların bu məsafəsi əsasında təyin edə bilirik. Belə ki, A və B nöqtələri klaster 1-ə təyin olunur, çünki bu nöqtələr mərkəz nöqtə 1-ə -(1,1) daha yaxın yerləşir nəinki mərkəz nöqtə 2 -(1,2). Eyni məntiqi ardıcıllıq ilə C, D, və E nöqtələri klaster 2-yə təyin olunurlar.
Addım 3. Mərkəzi nöqtələrin yenidən seçilərək yenilənməsi
Bu addımda, yeni mərkəzləri klasterdəki verilənlərin ortalaması əsasında hesablayırıq.
Klaster 1-in ortalaması : mərkəzi nöqtə M1= ortalama((1,1), (2,1))=(1.5,1) Klaster 2-nin ortalaması : mərkəzi nöqtə M2= ortalama((1,2), (4,3),(5,4))=(3.3,3)
Addım 2 və 3-ü bir daha təkrarlayaraq, mərkəzi nöqtələrə olan məsafəni bir daha almış oluruq:
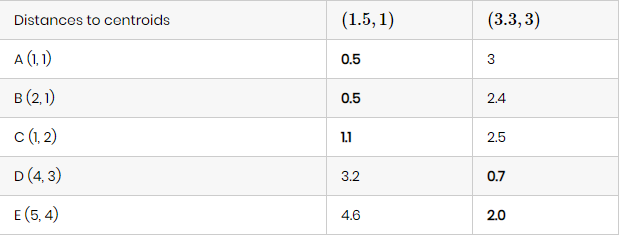
Məsafələrin hesablanması yuxarıdakı düstur ilə tapılır. Biz müşahidə edirik ki, C nöqtəsi artıq bu dəfə mərkəzi nöqtə -1-ə daha yaxınlaşıb (əvvəlki iteqrasiyada mərkəzi nöqtə -2-yə daha yaxın olmasına baxmayaraq). Bu səbəbdən, C nöqtəsi M1 klasterinə təyin olunur və digər nöqtələr əvvəlki aid olduqları klasterdə qalır.
Mərkəzi nöqtələrini yenidən hesabladıqda
Klaster 1-in ortalaması : mərkəzi nöqtə M1= ortalama((1,1), (2,1),(1,2))=(1.3,1.3) Klaster 2-nin ortalaması : mərkəzi nöqtə M2= ortalama(((4,3),(5,4))=(4.5,3.5)
Bu alqoritmi tamamlayır, çünki bir daha sonrakı iterasiya klasterlərdə dəyişiklik yaratmır və demək ki, nöqtə və mərkəzi nöqtələr dəyişmir.
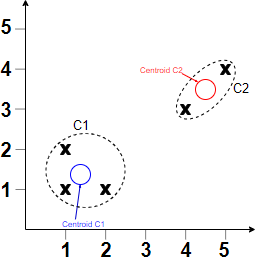
Bu kiçik nümunə yalnız K-means klaster alqoritmin işləməsini nümayiş etdirir.
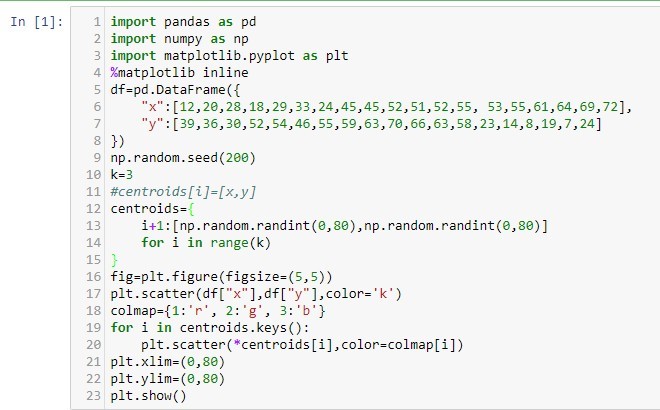
İndi isə verilənlər üzərində aparılan K-means analizini Python proqramlaşdırma dili vasitəsi ilə yerinə yetirək.
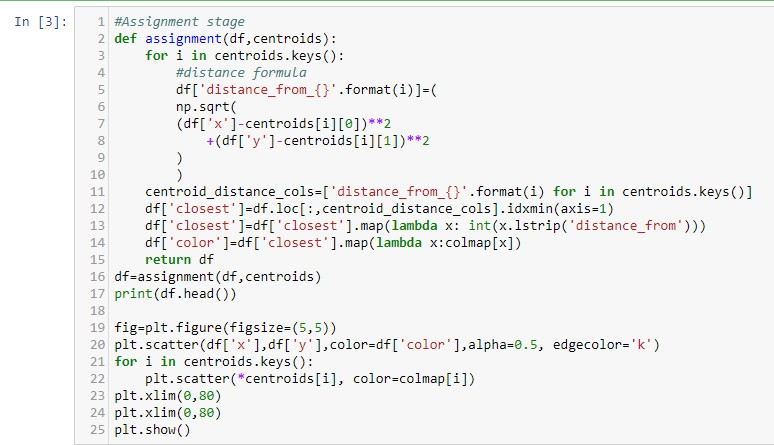
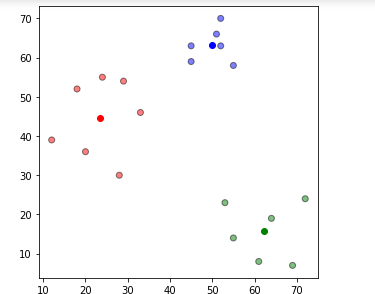
Aşağıdakı kodu işlətdikdə görürük ki qırmızı, yaşıl və göy rəngdə ixtiyari mərkəz nöqtəsi seçilmişdi.
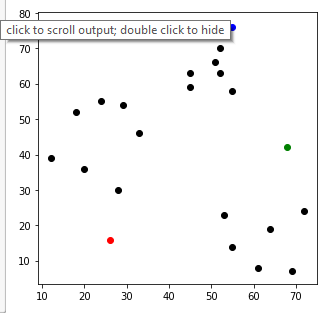
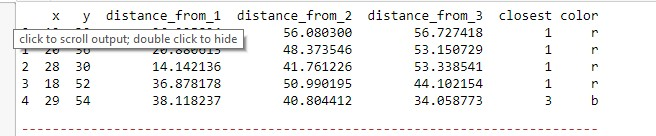
Təyin edilmə mərhələsində nöqtələr aid olduqları klasterlərə məsafə ölçüsünə əsaslanaraq təyin edilmişdilər. Məsələn: (12,39) nöqtəsi mərkəz 1 (klaster 1-ə) ən yaxın olduğundan 1 klasterinə təyin edilmişdir.
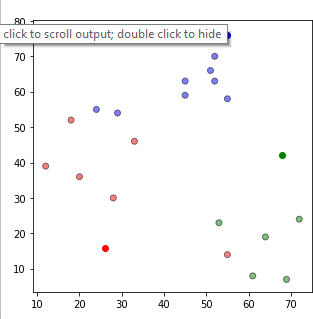
Mərkəzlərin yenilənməsi mərhələsi:Mərkəzi nöqtələrin yerini dəyişdiyini müşahidə etmiş oluruq.
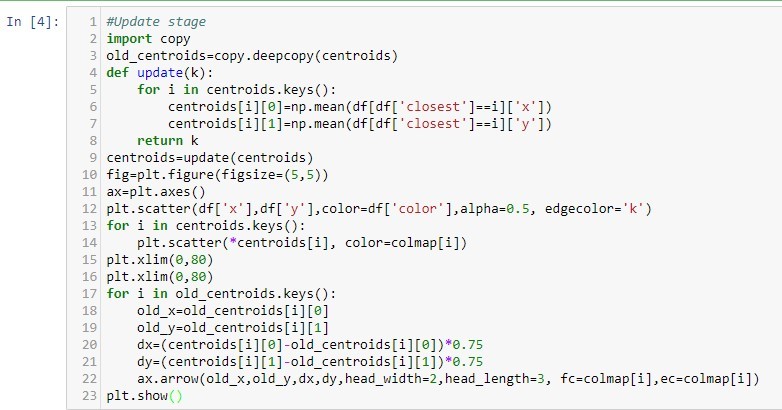
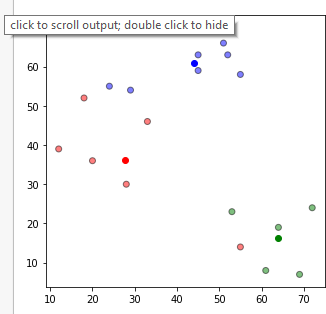
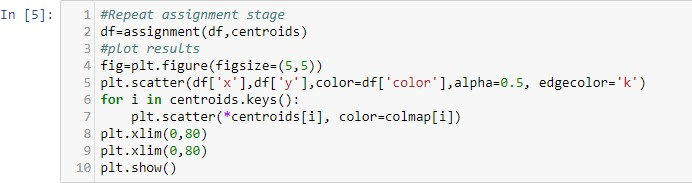
Təyin edilmə mərhələsi təkrarlanır:
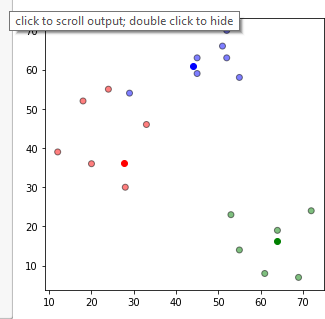
Bu kodu yazaraq iterasiyanın nə vaxt durmasını müəyyən etmiş oluruq.
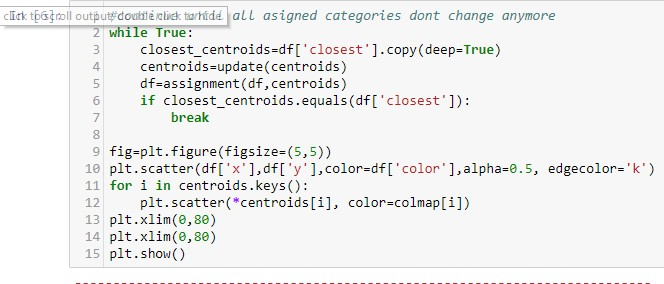
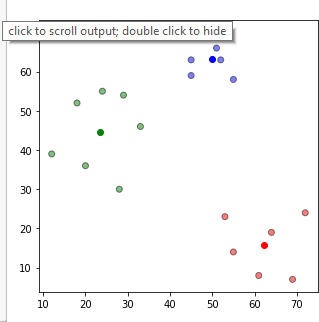
Python proqramlaşdırma dilinin SciKit Learn kitabxanası yuxarıdakı geniş yazılmış kodu hazır funksiyalar sayəsində sadələşdirilmiş təqdim edir:
Referans:
http://www.machinelearningtutorial.net/2017/02/14/k-means-clustering-example/ https://www.edureka.co/blog/k-means-clustering/
Daha çox oxu: